- {{item}}
- {{item}}
历史搜索
热门搜索
课程简介
众所周知,从去年的AlphaGo到今年无人驾驶大行其道,人工智能正在席卷全球,引发第4次工业革命,而AI的核心技术是机器学习和深度学习。无论是从事机器学习还是AI,都一定要多动手,否则 一切都是纸上谈兵。
今年7月份,「机器学习集训营」第一期开营,50个名额一抢而空,还有很多同学因未及时看到而错过第一期,本第二期特在第一期的基础上强力改进,继续沿用第一期线上线下相结合的授课方式,加强项目实训的同时引入线下BAT专家面对面、手把手教学方式(线下目前有北京、上海两个线下点)。依然突出BAT级工业项目实战辅导 + 一对一面试求职辅导,且继续提供3个月的GPU云实验平台供免费使用,更精讲面试常见考点。
本第二期增加上海50个名额,即北京加上海总计100个名额、历时3个月、10多个BAT级工业项目,更加保障每一位有追求的学员所学多、效率高、收获大
最终,不用再为遇到问题没人解答、为理论不知怎么应用到工业上、以及简历上没有项目经验而屡屡面试遭拒 而发愁。
培养目标: 从零开始,培养中高级机器学习工程师。挑战高薪、玩转AI。
PS:企业/高校团购集训通道请点击课程咨询。另,2人及2人以上组团报名,可各减500元,想组团者请加微信客服:julyedukefu
特色服务
-
全面涵盖机器学习重要知识点
集训营内容分为八大部分,涵盖教你零基础快速上手编程、数据爬取、数据分析、数据可视化、玩转大数据、机器学习从原理到实战、深度学习从原理到实战、BAT工业级大项目实战。
-
BAT专家级讲师 + 助教全方位辅导
我们拥有来自BAT的专家级讲师和数位助教,给你全程1v1般的定制辅导。通过GPU + jupyter notebook + GitHub,在线提交作业,然后讲师和助教在线批改作业,且提供可执行的交互式代码,从而每次课都是标准化配置,涵盖:GPU、原理、案例、数据、代码、作业。有问题,课上课后随时答疑,手把手教会为止。
-
线上线下项目实训
通过在线课程从头到尾掌握机器学习工业项目的各项流程、模型、算法,通过在线实训巩固强化实战所学,通过线下项目辅导练就ML工业项目的全栈能力。
-
提供GPU云实验平台
还原BAT真实生产环境,提供工业数据和国内首创的价值数十万的GPU云实验平台(提前装tensorflow、caffe、mxnet等主流DL框架和相关数据)。提供完善的实验平台供您动手、真枪实战,拒绝纸上谈兵。
-
简历优化
根据集训营实战项目,将涉及到的关键知识点和项目经历优化到您的简历中。
-
面试求职辅导 + 就业推荐
精讲机器学习工程师面试时常见考点/模型/算法,且BAT一线技术经理一对一模拟真实面试,从技术、表达等方面全方位提升您的面试能力。根据您的技术特长提供定制化的能力评估、就业指导以及包括BAT等一线互联网公司的工作机会推荐。3个月挑战年薪30~50万。
课程安排
-
第一阶段:零基础快速上手编程
- 在线课程:1-基本python类型、判断与循环流程等
- 在线实训:2-python基本练习题
- 在线课程:3-文件/数据读写、面向对象、第三方库等
- 在线实训:4-多种数据读写与面向对象练习
- 线下实训:5-python基本练习题 与 google python实战题
-
第二阶段:数据爬取得心应手
- 在线课程:1-requests bs4解析静态网页和selenium解析动态网页
- 在线实训:2-电商网站17huo和天气预报数据抓取、模拟百度关键字搜索
- 在线课程:3-模拟登陆与scrapy爬虫框架使用
- 在线实训:4-豆瓣电影数据抓取、创业邦投资机构数据抓取
- 线下实训:5-新闻网站与链家网数据爬取(基于scrapy实现)
-
第三阶段:数据分析全攻略
- 在线课程:1-pandas花式数据统计与分析技能
- 在线实训:2-pandas综合练习
- 在线课程:3-用pandas完成机器学习数据预处理与特征工程
- 在线实训:4-pandas完成Kaggle机器学习预处理
- 线下实训:5-美国大选、共享单车数据分析
-
第四阶段:可视化提升数据逼格技能get
- 在线课程:1-好用的python可视化利器matplotlib
- 在线实训:2-matplotlib完成Titanic和自行车租赁数据可视化
- 在线课程:3-自带各种数据拟合分析的可视化利器seaborn
- 在线实训:4-seaborn完成Titanic和自行车租赁数据可视化
- 线下实训:5-美国大选、共享单车可视化技能巩固与实战
-
第五阶段:玩转大数据
- 在线课程:1-hadoop与map-reduce
- 在线实训:2-手写map-reduce完成词频统计,制作词云
- 在线课程:3-Spark与大数据处理
- 在线实训:4-Spark大数据日志分析
- 线下实训:5-大数据分析处理案例
-
第六阶段:机器学习原理到实战
- 在线课程:1-机器学习流程、预处理、特征工程
- 在线实训:2-Kaggle机器学习比赛中的特征工程处理实战
- 在线课程:3-模型评判标准与部分机器学习有监督算法
- 在线实训:4-sklean接口熟悉与机器学习建模指导
- 线下实训:5-sklearn建模与使用
- 在线课程:6-机器学习有监督算法与无监督学习
- 在线实训:7-sklearn刷Kaggle比赛题
- 在线课程:8-机器学习集成算法与大杀器Xgboost/LightGBM
- 在线实训:9-Xgboost与LightGBM使用
- 在线课程:10-数据科学比赛精讲
- 在线实训:11-数据科学比赛练习赛
- 线下实训:12-集成算法与场景建模
-
第七阶段:深度学习原理到实战
- 在线课程:1-深度神经网络、google wide&&deep模型、腾讯通用CTR神经网络框架与实现
- 在线课程:2-卷积神经网络、caffe实战图像分类、Tensorflow实战图像风格变换实现
- 在线课程:3-循环神经网络、Tensorflow实战情感分析与文本生成实现
- 线下实训:4-Caffe&&Tensorflow实战
-
第八阶段:实际综合项目与就业指导
- 线下实训:1-自然语言处理项目
(文本数据抓取+spark/pandas数据分析+可视化+特征抽取+Sklearn/Spark机器学习建模+深度学习建模)
- 线下实训:2-分类与推荐系统实战
(音乐数据抓取+spark/pandas分析+可视化+协同过滤+隐语义模型+特征抽取分类建模)
- 线下实训:3-图像项目
(图像分类+图像检索)
- 线下实训:4-机器学习面试辅导
(面试注意点+常见面试考点精讲+简历指导+项目展示)
- 线下实训:1-自然语言处理项目
实战项目
-

实战项目1
python基本练习题 与 google python实战题
通过完成基本练习题,加深和巩固对python的认识和理解,挑战来自google的python实战题,熟练完成书写python代码解决各种问题。
-

实战项目2
新闻网站与链家网数据爬取
通过对新闻网站和链家网进行数据爬取,巩固静态网站爬取技巧,掌握技能包括requests库的使用、网页解析、正则表达式应用,中文文本处理等。
-

实战项目3
豆瓣与链家详情数据爬取
通过对豆瓣链家微信公众号等进行数据爬取,掌握登录网站数据获取的知识,掌握技能包括模拟登陆,数据爬取与解析,多类数据爬取。
-

实战项目4
去哪儿/携程与电商数据爬取
通过对去哪儿/携程旅游网站数据爬取,以及电商数据的爬取,掌握动态网站的抓取方法,包括动态网页渲染与解析。
-

实战项目5
pandas综合练习
通过pandas 100题练习,加深对pandas操作的熟悉度,同时通过对Kaggle案例进行数据处理,掌握实际场景下的数据操作工具。
-

实战项目6
大数据分析处理案例
通过对大文件日志的分析,熟悉hadoop,spark写map-reduce处理海量数据的方法,并对电商数据进行处理,get工业界常用大数据技能。
-

实战项目7
sklearn建模与使用
手把手带你get scikit-learn机器学习建模重要点借助于整理的简单资料,get迅速上手建模的技能,并学习如何进行模型调优,一步步优化自己的模型。期间的案例包括数个Kaggle与天池案例。
-
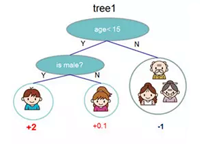
实战项目8
Xgboost与LightGBM使用
大部分情况下,为了取得好结果,我们会用集成模型,这个部分,我们设计了多个比赛和工业场景,帮助大家熟悉Xgboost和LightGBM的使用,使用树形Boosting模型达到较好拟合效果,同时又很好地控制过拟合。
-
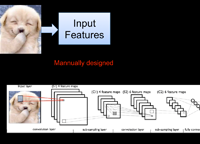
实战项目9
Caffe&Tensorflow实战
这个部分,将获得激动人心的深度学习库Caffe与Tensorflow搭建网络进行训练的全技能。我们将通过一个景点的图像识别transfer learning,到图像检索,到风格转换,一步步带大家学习库的使用,真正做到使用深度学习库解决实际的图像场景。
-

实战项目10
自然语言处理
针对工业界的一块应用场景:自然语言处理,设计了一个专题,我们将获取从文本数据抓取,到Spark/Pandas文本数据分析,到可视化,到多种文本特征抽取,到sklearn机器学习建模,到Spark机器学习建模,到利用深度学习建模的全部技能。
-

实战项目11
分类与推荐实战
我们针对电商最常见的推荐系统,设计了这个专题,从音乐数据抓取,到数据分析可视化,到利用协同过滤、隐语义模型、用户序列建模、learning to rank等方式完成一个推荐系统。
-

实战项目12
图像分类与检索
具体的图像分类与检索案例,在电商服装数据集上,进行分类与检索的实验。将获得图像数据预处理,Tensorflow建模与调优,基本图像检索与高级图像检索技能。
讲师介绍
-

寒老师
知名电商搜索广告负责人,多年实际ml/DL/dm项目经验,专注海量数据上机器学习算法的应用与优化。做过推荐系统、NLP、点击率预估、图像识别。讲课清晰易懂,擅长用实际数据、代码、案例说话,备受数千名学员好评。
-

冯老师
专注机器学习/人工智能,擅长解释机器学习中看似艰深晦涩的概念,熟悉模型背后的数学原理。曾工作于某知名私募的量化交易团队,参与高频交易中统计学习模型的开发。课堂上善于全程举例,所讲直达本质且不失生动有趣。
-

加号
主攻Deep Learning,牛津大学计算机系毕业,曾师从Google DeepMind的领军人物Prof. Nando de Freitas。UiiTech创始人,原TypeScore首席数据科学家。现就职于伦敦某投资银行的金融创新实验室(Innovation Lab),专注金融行业的AI构架与大数据产品研发。
-

林老师
原BAT高级技术专家,更早时期先后任职于微软、EMC等,从事过操作系统、数据库和云存储相关产品的研发。擅长Python数据分析、爬虫。曾多次作为面试官参与BAT/EMC校招面试与出题,善于剖析leetcode经典题型、助人入门、提高。
-

褚博士
芝加哥大学计算机博士,研究方向为NLP、ML、DL,熟练当前深度学习在NLP领域的模型与应用。
-

David陈
人大统计系数据挖掘与统计应用硕士,从事数据分析挖掘多年,开发过某金融公司量化自动交易系统。现为七月在线Python教学负责人,喜爱以数据去理解事物,擅长从零起步,一步步将复杂问题简单通俗阐述,备受广大学员欢迎。
时间安排
9月25日起正式上课,预计到12月底结束
- 在线课程周一20:00PM--22:00PM
- 在线实训周二20:00PM--22:00PM
- 在线课程周四20:00PM--22:00PM
- 在线实训周五20:00PM--22:00PM
- 线下实战周日09:00AM--13:00PM
线下实训地址:北京、上海。


线下实训
大牛讲师面授,学习氛围浓厚



课程咨询


常见问题
-
Q : 集训营的上课方式是怎样的?
A : 集训营采用线上线下相结合的方式,线上内容分为在线课程和在线实训,线下内容为线下集训,面对面实战项目辅导。
-
Q : 怎样的基础才能报名该集训营?
A : 学过编程、高数、概率统计,有一定的Python数据分析基础。
-
Q : 不在北京、上海怎么参加线下集训部分的课程?
A : 七月在线不提供住宿,但是可以帮助大家协调住宿。如果实在无法参加线下的集训部分,仍然可以获得线下集训的课程PPT和相关实验资料,您在自己实现具体项目时遇到任何问题可以随时咨询讲师。
Q : 集训营的上课方式是怎样的?
A : 集训营采用线上线下相结合的方式,线上内容分为在线课程和在线实训,线下内容为线下集训,面对面实战项目辅导。
Q : 怎样的基础才能报名该集训营?
A : 学过编程、高数、概率统计,有一定的Python数据分析基础。
Q : 不在北京、上海怎么参加线下集训部分的课程?
A : 七月在线不提供住宿,但是可以帮助大家协调住宿。如果实在无法参加线下的集训部分,仍然可以获得线下集训的课程PPT和相关实验资料,您在自己实现具体项目时遇到任何问题可以随时咨询讲师。