 分享领红包
分享领红包

扫描二维码分享:
分享给好友,每有1人领取红包,您将获得相同奖励。自己也可以领取哦〜
历史搜索
热门搜索
本大数据集训营从Hadoop基础讲解,贯穿数据采集、传输、存储、计算、展示等各个环节,着重讲解企业中如何使用spark、MapReduce、hive、flume、sqoop等各个组件,并附有经典企业案例讲解,案例均来自一线互联网工业项目。
另,讲师团队堪称大厂豪华级大数据专家讲师团队,且根据最近的大数据人才需求,加入elasticsearch和数据仓库模型等内容,以及设计了三大企业级项目,并标准化项目流程:
最后,在第八阶段设置了大数据求职面试辅导,包括大数据面试求职准备工作讲解、常见大数据面试题目解析等内容。
一切为了大家更好的就业、转型、提升。
培养目标: 从零开始,由Hadoop入门,打造大数据开发工程师之路。
PS:企业/高校团购集训通道请点击 课程咨询,
我们拥有来自BAT的专家级讲师和数位助教,给你全程1v1般的定制辅导。通过一个个项目实战从头到尾掌握大数据的典型应用场景,从而练就大数据工业项目的全栈能力。且有问题,课上课后随时答疑,手把手教会为止。
本期集训营实战项目,涵盖集群搭建、hive优化、数据仓库搭建、数据采集平台、离线计算平台、实时计算平台、多维分析平台、直播、短视频APP用户行为分析、日志监控(搜索、分析、报警)平台等一线互联网实用案例。
还原BAT真实生产环境,提供工业数据和国内首创的价值数十万的云实验平台(提前装hadoop集群、hive、spark等环境)。提供完善的实验平台供您动手、真枪实战,拒绝纸上谈兵。
从Hadoop起步,一上来就实战BAT工业项目。且根据集训营实战项目,将涉及到的关键知识点和项目经历优化到您的简历中。
精讲大数据开发工程师面试时常见考点/组件/算法,且BAT大厂架构师1v1模拟真实面试,从技术、表达等方面全方位提升您的面试能力。根据您的技术特长提供定制化的能力评估、就业指导以及包括BAT等一线互联网公司的工作机会推荐。2个半月挑战年薪30~50万。
在线视频:大数据与Hadoop生态介绍
在线实训:搭建HDFS伪分布式集群
在线视频:大数据存储系统HDFS
在线实训:搭建Zookeeper、HDFS、YARN的分布式集群
在线视频:分布式资源管理框架Yarn
在线视频:分布式计算框架MapReduce与Hive SQL
在线视频:数据收集工具Flume、Beats介绍与原理
在线实训:Flume收集日志数据到HDFS或者Kafka
在线视频:数据库同步工具Alibaba Canal介绍与原理
在线实训:通过Canal将MySql数据导入到HDFS中
在线视频:高吞吐消息队列Kafka介绍(一)
在线视频:分布式数据库Hbase
在线视频:spark技术栈发展概述与spark应用开发API介绍
在线实训:Spark RDD API分布式构建搜索引擎的分布式倒排索引
在线视频:流式计算简介及spark streaming
在线实训:Kafka + Spark Streaming构建实时监控大屏
在线视频:流式计算实战
在线视频:spark运行模式及原理
在线视频:Spark sql讲解
在线实训:基于spark sql 2.4.0 的王者荣耀英雄分析
在线视频:Spark集群监控与问题排查
在线实训:spark history server搭建部署; 从监控入手进行日志查错与优化
在线视频:Spark core核心讲解与Spark性能调优
在线视频:使用Spark开发一套通用的流和批计算引擎
在线视频:数据仓库基础
在线视频:数据仓库的数据治理与任务调度
在线视频:OLAP分析场景下的技术架构
在线视频:Flink基础介绍
在线视频:Flink核心特性讲解
在线视频:开发用户行为分析的Flink程序
在线视频:日志平台介绍及Elasticsearch基础
在线视频:错误日志平台搭建
在线视频:日志平台架构优化与Spark集成
在线视频:大数据面试求职准备工作讲解
在线视频:常见大数据面试题目解析
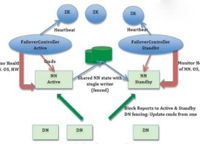
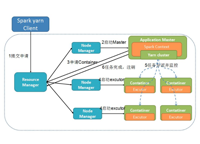
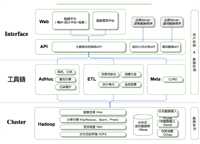
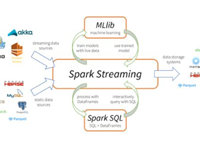





7年Hadoop,Spark大数据行业经验,曾在微博、乐视、新浪负责过多个业务线的PB级数据仓库和流式计算,负责的大数据项目在Github上开源,目前在国内某一线互联网公司任职。

目前在BAT某业务中负责金融风控场景的算法应用,毕业于复旦大学,毕业后在中国电信数据中心大数据团队负责大数据系统的建设与产品开发,主要负责Spark各模块的运维、调优、开发与算法应用,曾任数据挖掘组leader。

某大厂担任数据架构专家,多年大数据从业经验,曾工作于EMC,百度等公司,目前做大数据基础架构以及开发相关工作,团队spark技术负责人,有hadoop,spark,hbase,kafka,flume,es,redis等大数据组件的应用经验,Apache Spark Contributer。

某大厂数据架构师,多年大数据从业经验,从离线数据处理到实时数据计算,深入了解数据计算解决方案,有hadoop,hive,spark,hbase,couchbase,kudu,impala,druid等众多大数据组件应用经验。
根据课程安排随到随学,为期2个多月
当前报名{{list.currentuser}}人,还剩{{list.remuser}}个特惠名额。











